The problem with manual ML research
Training a document forgery detection model is not a one-time event. New fraud techniques emerge constantly: AI-generated invoices, edited bank statement screenshots, fake receipts produced by image generation models. The model that works today needs to keep improving to stay ahead.
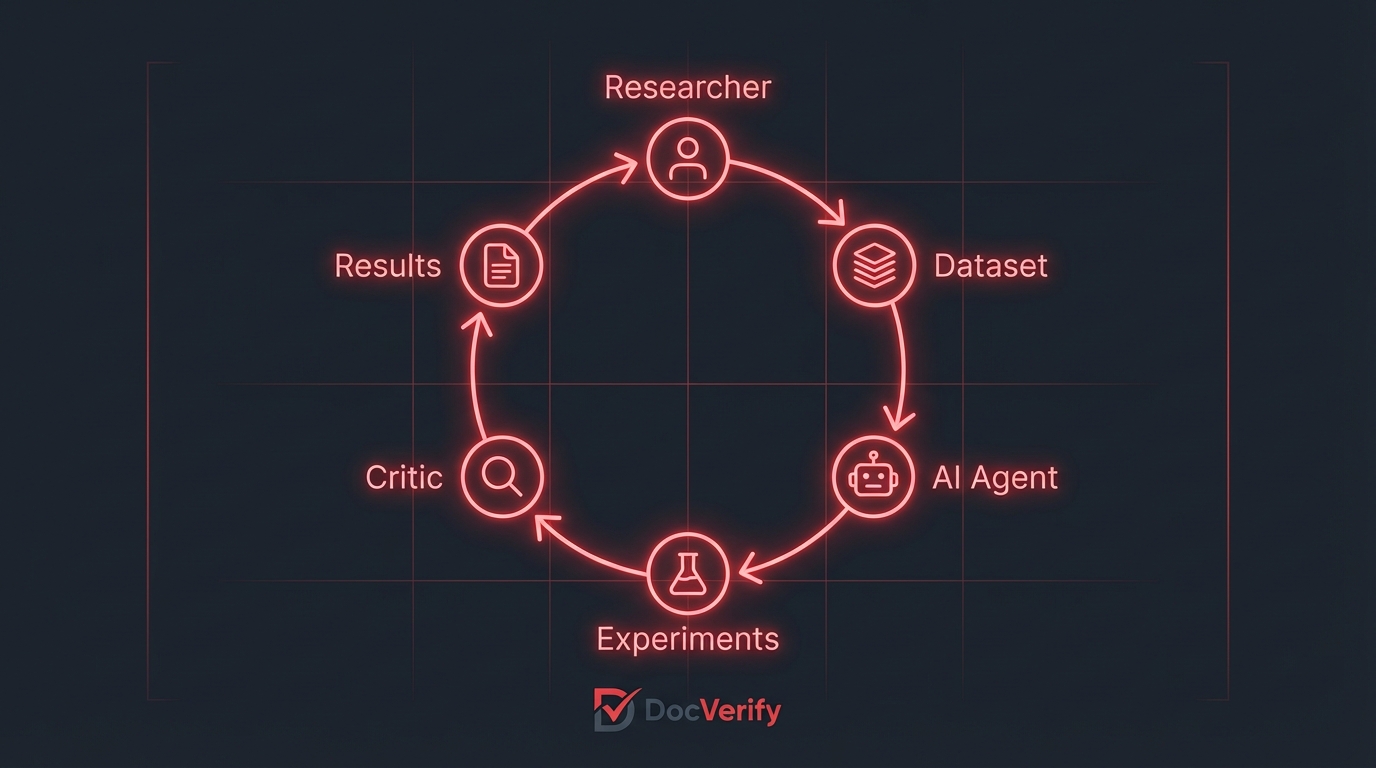
The traditional approach is a researcher picks a hypothesis, modifies the model, runs a training job overnight, reads the results in the morning, and repeats. Slow, expensive, and gated by human attention. We wanted something different. We wanted to describe what needs to happen and let a system figure out how -- continuously, without waiting for a sprint.
What we ended up building is less of a pipeline and more of a loop. A loop with a human in it, but not blocking it.
Stage one: researcher and AI work the problem together
Before any automated training runs, a researcher and an AI assistant sit down and think through the problem. What are the current failure modes? Where is the model losing precision? Are there new forgery types showing up in production that the training distribution does not cover?
Together they design the experiment direction, define the evaluation criteria, and prepare or curate the dataset. The AI assistant helps surface patterns in the evaluation data, draft experiment hypotheses, and identify gaps in the current approach. The human makes the calls about what matters.
This stage produces two things: a cleaned and labelled dataset ready for training, and a program specification file that describes what the autonomous loop should try to optimise. That spec is what the agent reads to understand its job.
Stage two: the autoresearch loop kicks off
Once the spec and dataset are ready, an AI coding agent is launched on a GPU-backed virtual machine. It reads the program specification, then starts running experiments back to back, autonomously, for as long as you let it.
Each iteration goes like this:
- Read the program spec to understand current direction and any new human instructions
- Propose and implement one change to the model or training setup
- Commit the change to git with a description of what was tried and why
- Run the training job on the GPU instance
- Evaluate on the held-out validation set and compute a composite score
- Log the result to a TSV file: commit hash, score, memory usage, status, and a short description
- If the score improved: keep the commit and continue forward
- If not: git reset to the previous state and try a different direction
- Repeat
The commit-before-run pattern is deliberate. It means every experiment is recoverable. If training crashes, runs out of memory, or produces garbage output, the codebase can be cleanly reset to the last known good state. The git log becomes a record of what worked, not a graveyard of half-finished experiments.
The TSV file is the scoreboard. Every row is a single experiment: what commit it ran from, what score it got, how much GPU memory it used, whether it succeeded or was reverted, and a one-line human-readable description. At a glance you can see the shape of the search -- which directions are producing gains, where things got stuck.
Stage three: the critic
After each experiment, an independent AI instance reviews what happened. This is not the same agent that ran the experiment. It is a separate process with no stake in the outcome -- its job is to read the experiment log and produce an honest assessment.
The critic appends its review to a critic log that is separate from the main research log. This matters for a few reasons. The research log is operational: what ran, what score, what status. The critic log is evaluative: was the direction sensible, are there patterns in the failures, is the agent getting stuck in a local optimum, are there obvious things it has not tried?
Keeping them separate makes both more useful. You can read the critic log to understand the shape of the search without wading through operational details, and you can audit the research log without it being cluttered with commentary.
Over a long run, the critic log becomes genuinely valuable. It surfaces things like: "this class of experiments has not improved score in 12 iterations, might be worth switching direction" or "memory usage has been creeping up across the last 8 commits, worth investigating." The agent does not always catch these patterns on its own.
Steering without stopping
One thing we got right early on: humans need to be able to inject direction into a running loop without stopping it.
We use a HUMAN_LOG file for this. At the start of every loop iteration, the agent reads the file and acknowledges any new instructions before proceeding. If a human adds a note like "we are seeing false negatives on AI-generated documents with no compression artifacts, prioritise format-agnostic features," the agent reads it on the next iteration, adjusts its experimental direction, and records that it received and acted on the instruction.
This is the difference between supervision and interruption. You do not need to kill a run that has been going for six hours just because you want to nudge it. You write a note, and the agent picks it up on its own timeline.
It also creates an audit trail. The HUMAN_LOG shows what instructions were given and when. The research log shows what the agent did after each instruction. You can verify that directives were followed and trace how the search changed in response.
Why pixel-level detection makes this hard
Most document verification tools work at the field level -- they OCR the document and check whether the numbers look plausible. That is not verification. That is reading.
DocVerify's model works at the pixel level. It analyses forensic properties: statistical noise patterns, learned manipulation signals, edge consistency between regions, format-agnostic features that hold up whether the document is a JPEG scan or a lossless PNG screenshot.
The output is a heatmap -- a per-pixel probability of tampering. Not just "this looks fake" but "here is exactly which region was modified." That is useful for downstream workflows: an automated system flags the document, a human reviewer can immediately see why.
What makes this hard for the autoresearch loop is that the search space is genuinely large. The model architecture, the forensic feature extractors, the loss function weighting, the training strategy -- all of these interact. An improvement in one dimension can expose a bottleneck in another. The agent needs enough latitude to explore combinations, not just one variable at a time, while staying coherent enough to make consistent progress.
The critic helps here. When the agent starts thrashing -- making changes that do not compound into consistent gains -- the critic tends to notice before the score trend makes it obvious.
What the results look like
After a long run, the TSV file tells a story. Early experiments tend to be broad -- trying different architectural directions, establishing a baseline. As the search narrows, experiments get more specific: adjusting loss weighting, refining feature extractors for particular forgery types, tuning for the edge cases the critic flagged.
The git history reflects this. The commits that stick are the ones that moved the composite score in the right direction. Everything else was automatically reverted. The branch tip is always the best model found so far.
For document fraud, this matters for the same reason the loop was built: the threat is not static. As detection improves, forgery techniques adapt. AI image generation gets meaningfully better every few months. The only appropriate response is a model that keeps improving at the same pace, automatically, without waiting for a research sprint.
What this means for API users
If you are using DocVerify's API to verify documents in your workflow, this infrastructure means the model you call today is not the model you will call in six months. It improves continuously, without any changes on your end.
The API is stable. The endpoint does not change. The model underneath gets better -- handling new forgery types, reducing false positives on clean documents, improving precision on the tampered regions it flags.
Integrate DocVerify into your AI agent pipeline:
- REST API with JSON responses and pixel-level heatmap output
- MCP server for Claude Code and other AI agent frameworks
- Not just a verdict -- exact coordinates of the tampered region
- Works on JPEG, PNG, and PDF
Get started at docverify.app